

Développé par l'entreprise britannique DeepMind spécialisée dans l'intelligence artificielle et rachetée par Google en 2014, AlphaGo s'est fait connaître du grand public en battant des joueurs professionnels de go.
Ces victoires avaient été présentées comme de véritables exploits pour une intelligence artificielle, en tenant compte du nombre gigantesque de combinaisons (de l'ordre de 10^170) pour ce jeu de plateau inventé en Chine il y a trois mille ans, et où l'intuition humaine s'exprime.
AlphaGo a pu s'appuyer sur une imposante puissance de calcul, un réseau de neurones artificiels et des techniques d'apprentissage automatique. Via une phase d'apprentissage par renforcement, il se perfectionne en étudiant des parties humaines et en jouant contre lui-même.
AlphaGo a trouvé son maître… AlphaGo Zero. DeepMind explique que contrairement aux précédentes versions d'AlphaGo, AlphaGo Zero a appris à jouer au jeu de go en jouant seulement des parties contre lui-même. L'étape d'entraînement avec des milliers de parties humaines pour apprendre à jouer a été zappée.
" AlphaGo Zero apprend à jouer au jeu de go sans données humaines ", souligne DeepMind, même si pour autant, les algorithmes d'apprentissage utilisés sont de conception humaine et les règles de base du jeu de go ont été fournies. Par ailleurs, DeepMind vante une simplification de l'architecture d'AlphaGo Zero avec pour conséquence de réduire les ressources informatiques nécessaires.
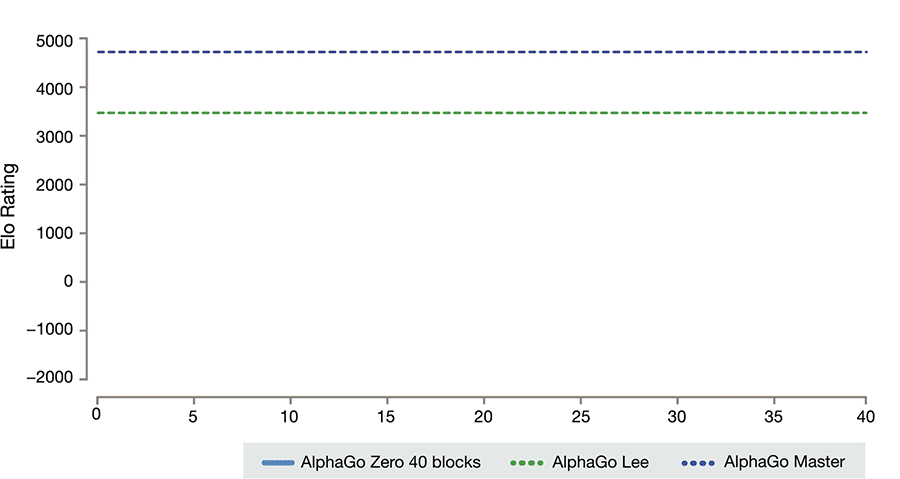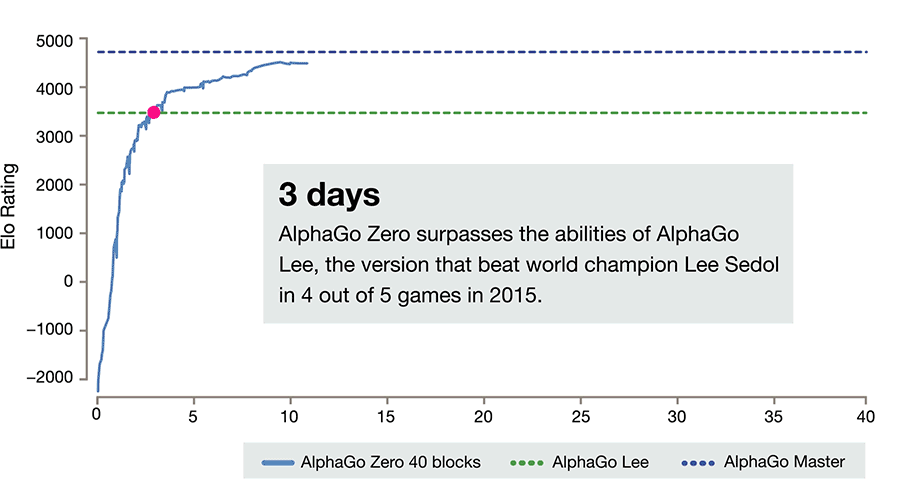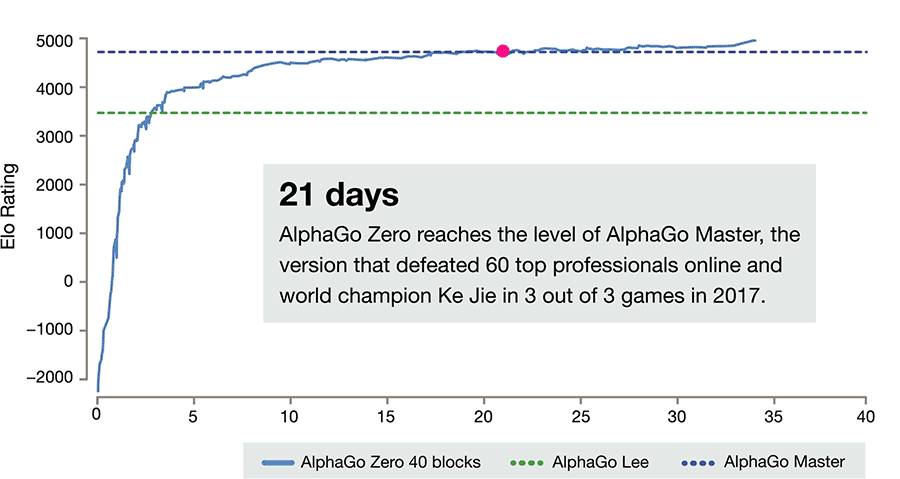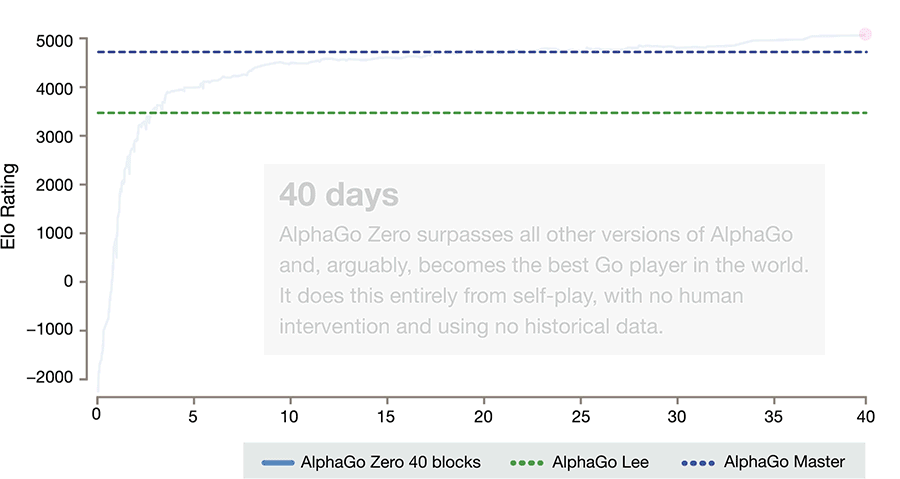
En seulement 40 jours d'apprentissage par renforcement, AlphaGo Zero a surpassé la précédente version plus puissante d'AlphaGo, devenant de facto le meilleur joueur de go au monde, et ce en étant donc son propre professeur.
Pour DeepMind, la finalité n'est évidemment pas le jeu de go. Avec des techniques similaires, et sans donc des données humaines, les domaines tels que " le repliement des protéines, la réduction de la consommation d'énergie ou la recherche pour de nouveaux matériaux révolutionnaires " sont évoqués.
