



Anthropic introduit le modèle Claude Opus 4.5. Il fait suite à la mise à jour estivale Claude Opus 4.1 et complète la série 4.5 de modèles débutée en septembre, dont Claude Sonnet 4.5.
Claude Opus 4.5 se positionne comme une réponse directe aux récentes annonces de Google avec Gemini 3 et d'OpenAI avec GPT-5.1, et s'accompagne d'une stratégie tarifaire agressive.
Le coût d'accès à l'API a été réduit, passant à 5 dollars par million de tokens en entrée et 25 dollars en sortie, rendant les capacités de pointe plus accessibles aux entreprises et aux équipes de développement.
Quelles sont les performances réelles face à la concurrence ?
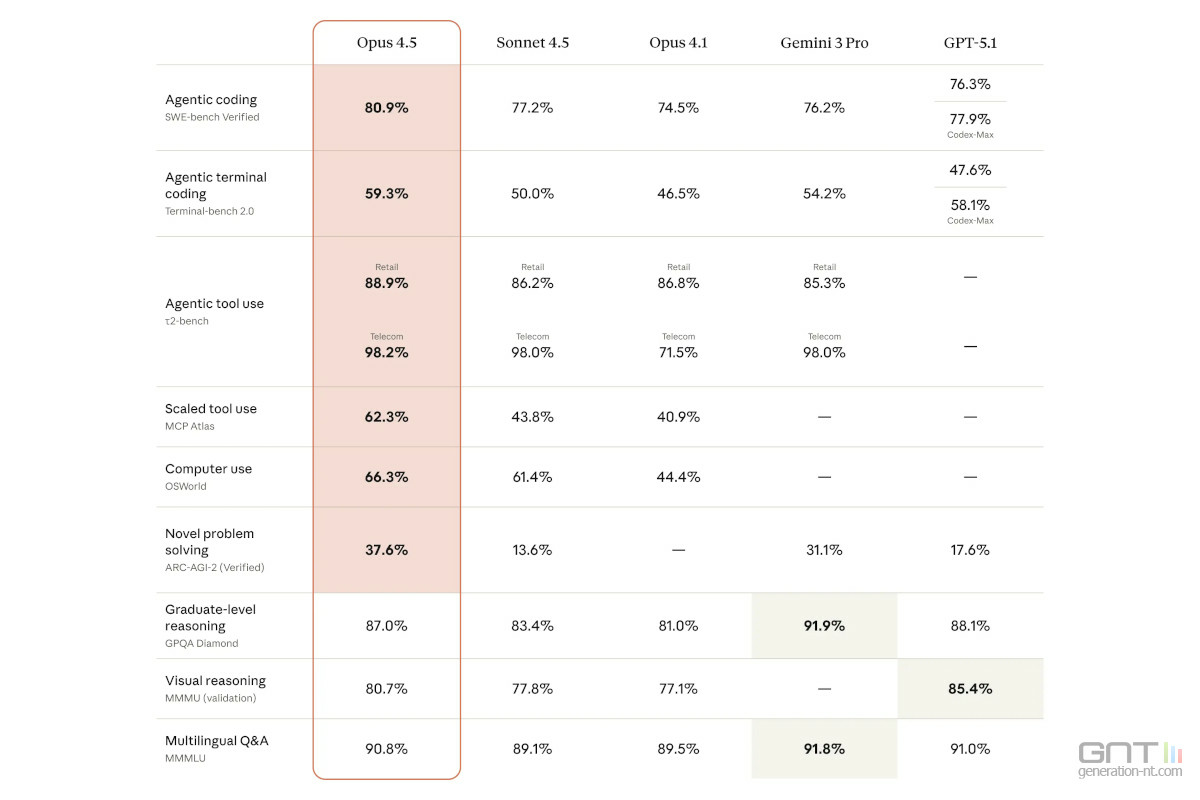
Le nouveau venu s'impose comme une référence technique, notamment dans le développement logiciel.
Selon les tests internes rapportés par Anthropic, Claude Opus 4.5 devient le premier modèle à franchir la barre des 80 % de réussite sur SWE-Bench Verified, atteignant précisément 80,9 %. Claude Opus 4.5 devance ainsi GPT-5.1-Codex-Max d'OpenAI (77,9 %) et Gemini 3 Pro de Google (76,2 %).
Anthropic affirme que le modèle est significativement meilleur pour les tâches quotidiennes comme la recherche approfondie, permettant aux ingénieurs de déléguer des tâches de refactoring complexes avec une fiabilité inédite.
Une adaptation aux besoins des développeurs
Au-delà de la puissance brute, c'est l'intégration des outils et la flexibilité d'utilisation qui sont mises en avant.
Anthropic introduit un paramètre " effort " dans son API, permettant aux utilisateurs d'arbitrer dynamiquement entre la rapidité d'exécution et la profondeur du raisonnement.
L'approche permet au modèle de compresser sa mémoire sans interrompre les sessions de travail prolongées, un atout majeur pour les projets agentiques nécessitant une continuité.
La sécurité et les agents autonomes sont-ils à la hauteur ?
L'utilisation d'agents autonomes sur de longues durées soulève inévitablement des questions critiques de sécurité, notamment face aux tentatives de manipulation.
Bien que Claude Opus 4.5 ne soit pas totalement immunisé, le rapport technique indique qu'il a refusé 100 % des requêtes de codage malveillant lors des évaluations spécifiques.
Cependant, des failles subsistent dans des scénarios de cybercriminalité plus larges, où le modèle a bloqué environ 88 % des demandes nuisibles.

