



La société chinoise DeepSeek lance DeepSeek-Math-V2, un modèle d'intelligence artificielle open-source spécialisé en mathématiques. Atteignant des performances de niveau médaille d'or aux Olympiades Internationales de Mathématiques, il se distingue par sa capacité d'auto-vérification, privilégiant un processus de raisonnement rigoureux plutôt que la seule justesse de la réponse finale pour repousser les limites de l'IA.
Jusqu'à présent, la course à la performance des IA en mathématiques se concentrait sur un objectif principal : obtenir la bonne réponse. Cette approche, bien qu'efficace pour saturer les benchmarks, présentait une faille majeure.
Une solution correcte ne garantissait en rien la validité du cheminement logique emprunté pour y parvenir. C'est précisément ce paradigme que l'entreprise chinoise DeepSeek entend bousculer avec son nouveau modèle.
Du résultat au processus : une nouvelle approche
La startup DeepSeek a mis au point un système complexe pour son modèle Math-V2. L'idée centrale est de délaisser la simple validation du résultat final pour se concentrer sur la rigueur de chaque étape.
Pour y parvenir, le modèle s'appuie sur une architecture à plusieurs niveaux, à la manière d'un tandem "enseignant-superviseur".

Un premier agent, le vérificateur, évalue la justesse d'une démonstration en lui attribuant une note de 0 à 1. Dans le même temps, un méta-vérificateur s'assure que les critiques du premier sont bien fondées et ne relèvent pas d'hallucinations.
Cette double couche de contrôle permet de fiabiliser l'évaluation et de s'assurer que le processus de raisonnement est rigoureux.
Un "étudiant" honnête et auto-réflexif
Le véritable tour de force réside dans la manière dont le générateur de preuves, "l'étudiant", est entraîné. Le système ne récompense pas seulement la bonne réponse, mais aussi l'honnêteté. Après avoir proposé une solution, le modèle doit immédiatement l'auto-évaluer et s'attribuer une note.
S'il se trompe mais identifie lui-même son erreur, il est récompensé. À l'inverse, une confiance aveugle dans un résultat erroné est pénalisée. Cette mécanique pousse l'IA à un raisonnement mathématique plus profond et à une forme d'auto-critique avant de finaliser sa proposition, une approche conçue pour limiter les erreurs et renforcer la fiabilité des démonstrations.
Des performances qui rivalisent avec l'élite humaine
Les résultats sont à la hauteur de l'ambition. DeepSeek-Math-V2 a obtenu des scores équivalents à une médaille d'or lors de simulations sur des problèmes de l'Olympiade internationale de mathématiques (IMO) de 2025 et de l'Olympiade Chinoise de Mathématiques (CMO) de 2024.
Le modèle a même atteint le score impressionnant de 118 sur 120 à l'examen Putnam, dépassant largement le meilleur score humain fixé à 90.
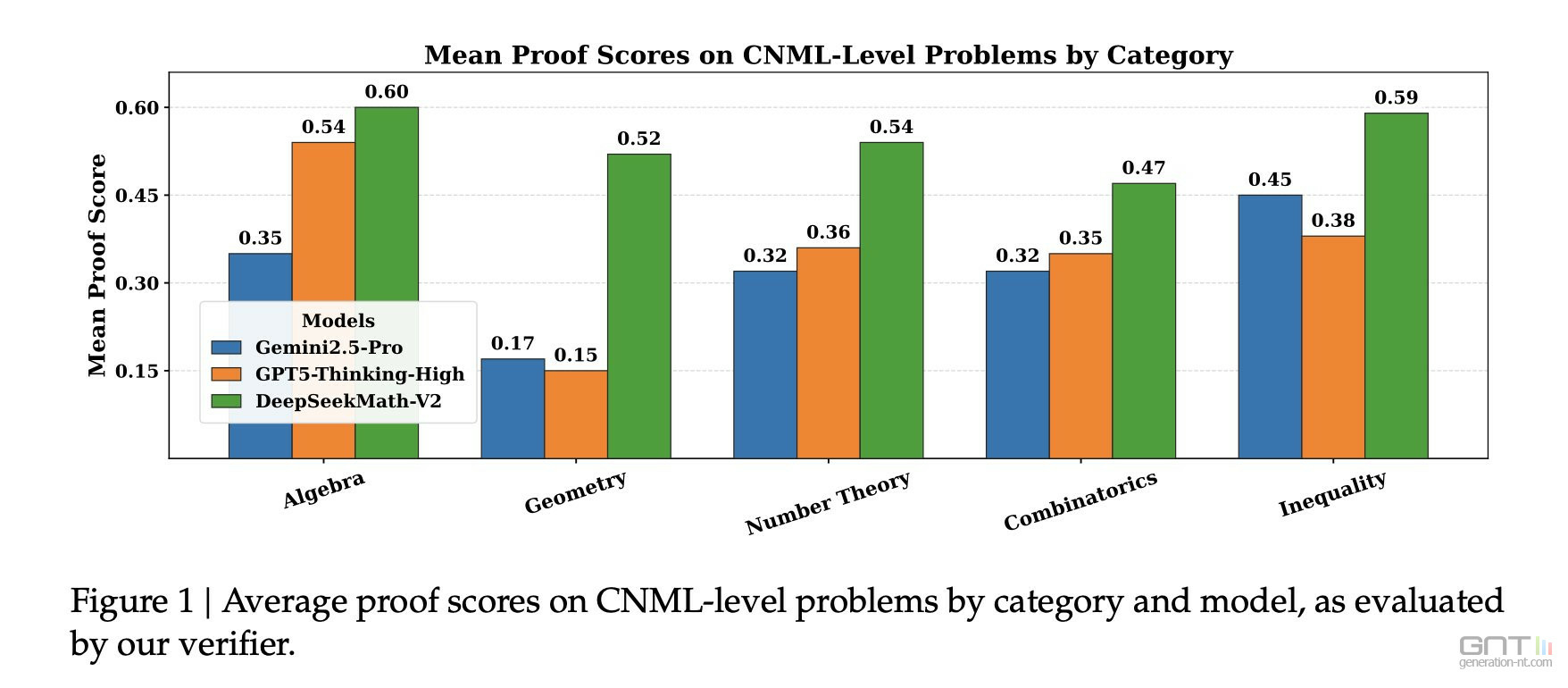
En rendant son modèle open-source sur des plateformes comme Hugging Face et GitHub, DeepSeek se positionne en concurrent direct des géants américains comme Google DeepMind et OpenAI, qui gardent leurs propres modèles propriétaires.
Cette transparence pourrait non seulement accélérer la recherche, mais aussi redistribuer les cartes dans une économie de l'intelligence artificielle jusqu'ici dominée par les laboratoires occidentaux, ouvrant la voie à des systèmes mathématiques encore plus performants.

