



La gestion des contextes longs représente l'un des défis majeurs pour les grands modèles de langage (LLM). Plus un document est volumineux, plus le nombre de "tokens", c'est à dire les unités de texte traitées par l'IA, explose, entraînant une consommation de mémoire et une charge de calcul proportionnelles.
La startup chinoise DeepSeek, connue pour ses modèles performants et économes, s'attaque à ce goulot d'étranglement avec une approche novatrice.
Comment DeepSeek-OCR parvient-il à "compresser" l'information ?
L'hypothèse centrale de DeepSeek est que traiter un texte sous forme d'image peut s'avérer bien plus efficace que de manipuler directement le texte numérique. Le nouveau modèle d'IA multimodal, baptisé DeepSeek-OCR, met cette idée en pratique grâce à une architecture en deux parties.
Le DeepEncoder, un encodeur visuel de 380 millions de paramètres, analyse l'image du document et en produit une version compressée. Pour y parvenir, il combine le modèle SAM de Meta pour la segmentation d'image et CLIP d'OpenAI pour lier images et texte.
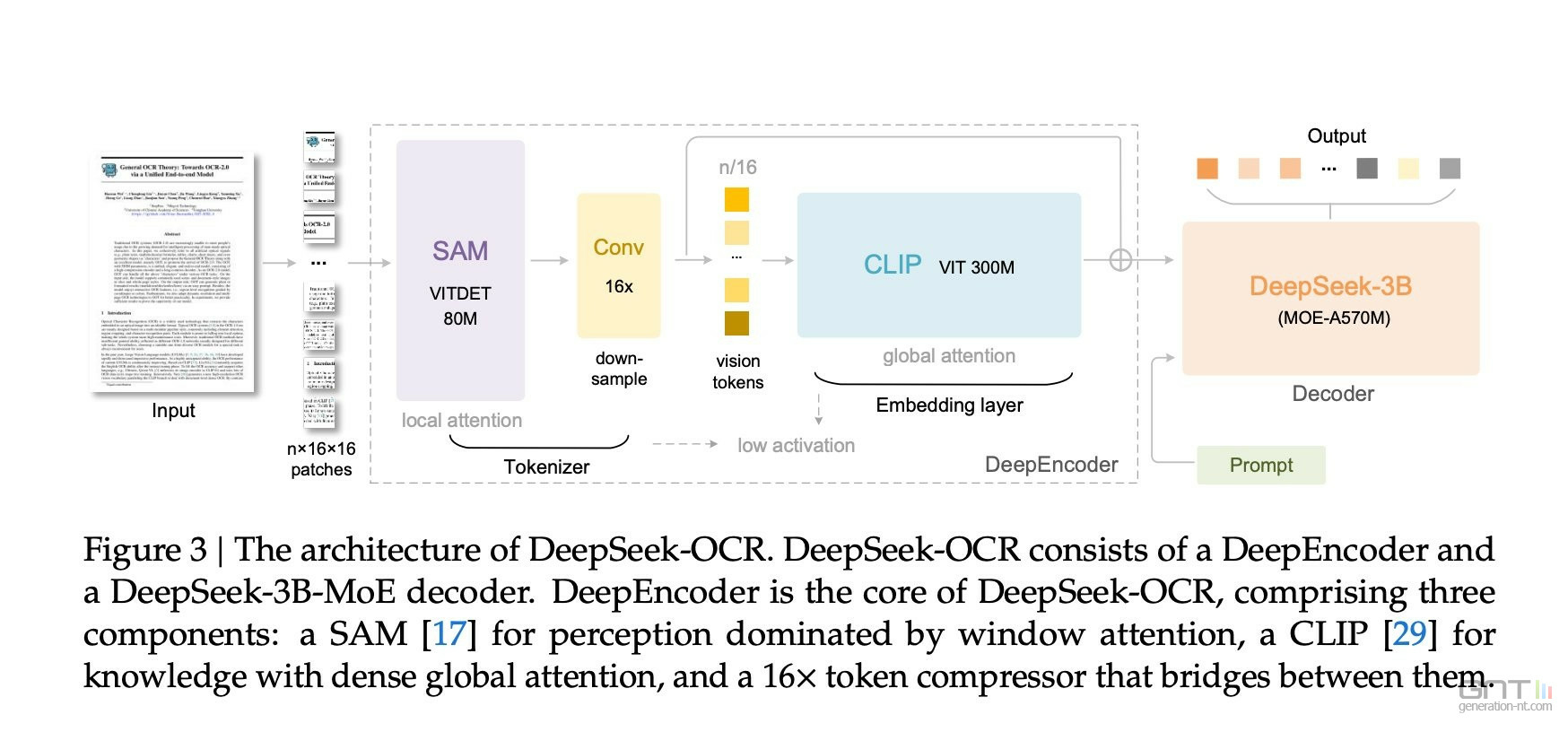
Un compresseur réduit ensuite drastiquement le nombre de tokens visuels. De l'autre côté, un décodeur basé sur DeepSeek3B-MoE se charge de générer le texte à partir de cette représentation compacte.
Le résultat est une réduction spectaculaire : une image de 1024x1024 pixels, qui nécessiterait initialement 4 096 tokens, est traitée avec seulement 256 tokens.
Une efficacité redoutable sur le terrain
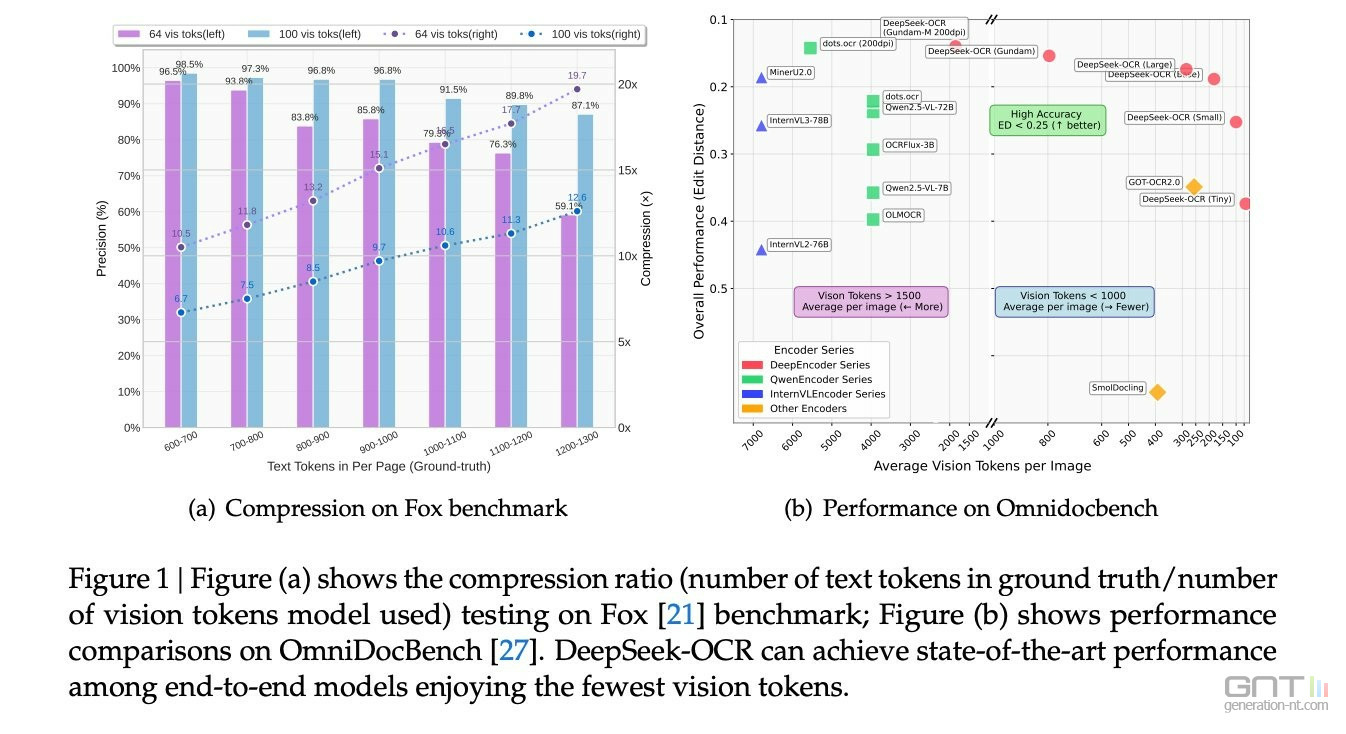
Les performances annoncées sont impressionnantes. Selon le document technique de l'entreprise, DeepSeek-OCR peut atteindre un facteur de compression allant de 7 à 20 fois tout en conservant 97 % de l'information originale.
Cette efficacité permet de diminuer significativement les coûts de calcul. Lors des tests sur le benchmark OmniDocBench, le modèle surpasse ses concurrents comme GOT-OCR 2.0 en utilisant moins de la moitié des tokens.
Cette optimisation se traduit par une capacité de traitement massive. Un unique GPU Nvidia A100 peut traiter plus de 200 000 pages par jour. En déployant une infrastructure de 20 serveurs équipés de huit de ces puces, le débit grimpe à 33 millions de pages quotidiennes.
Une telle puissance de feu pourrait considérablement accélérer la constitution de jeux de données pour entraîner d'autres modèles d'intelligence artificielle.
Flexibilité et accessibilité : une porte ouverte sur l'avenir ?
Le système offre également une certaine polyvalence. Il prend en charge une centaine de langues et une grande variété de types de documents, des textes simples aux diagrammes, en passant par les formules chimiques et les figures géométriques.
Pour s'adapter à la complexité de chaque page, plusieurs modes de résolution sont proposés, du plus économe (64 tokens) au plus détaillé, baptisé "Gundam" (jusqu'à 800 tokens).
En rendant le code et les poids du modèle publiquement disponibles sur des plateformes comme Hugging Face et GitHub, DeepSeek fait un pas de plus vers la démocratisation de ces outils.
Cette démarche open source permet aux chercheurs et développeurs du monde entier de s'approprier la technologie. La grande question est maintenant de savoir comment cet outil sera utilisé pour construire la prochaine génération de modèles, nourris par des volumes de données d'entraînement inédits.

