



Le mois dernier, Mistral AI a dévoilé son tout premier modèle d'IA multimodal Pixtral (Pixtral 12B). Ce mois-ci, la start-up française d'intelligence artificielle générative présente une nouvelle famille de modèles portant le nom de Ministraux.
Ces modèles sont conçus pour l'edge computing et une exécution sur les appareils comme les ordinateurs portables et les smartphones. Ils incarnent des solutions efficaces et à faible latence pour les applications sur les appareils, telles que la traduction, les assistants intelligents, l'analyse locale et la robotique.
Ministral 3B et Ministral 8B sont introduits à l'occasion du premier anniversaire de la publication du grand modèle de langage open source Mistral 7B qui avait marqué les esprits. À l'époque, il s'agissait du modèle de langage le plus puissant au regard de sa taille.
Des benchmarks forcément flatteurs
Les deux modèles Ministraux ont une fenêtre de contexte de 128 000 tokens. Pour Ministral 8B, une technique pour limiter la durée d'attention de chaque token permet une inférence plus rapide et efficiente en termes de mémoire.
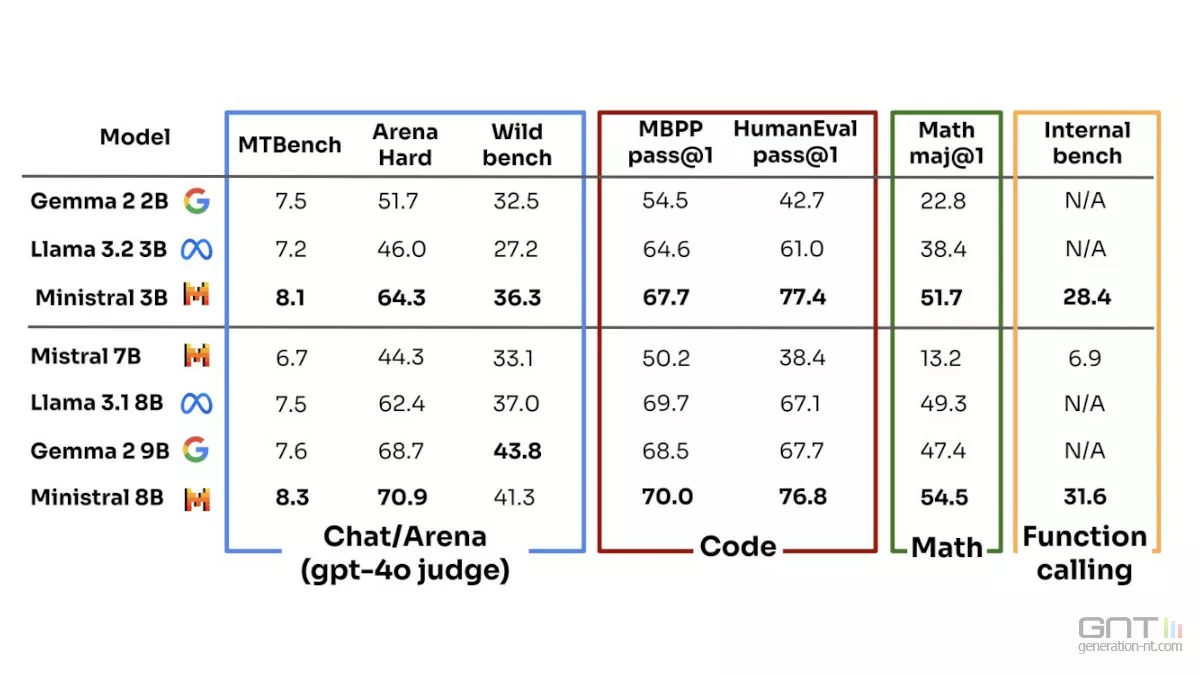
Mistral AI souligne que le plus petit modèle Ministral 3D surpasse Mistral 7B sur la plupart des benchmarks pour l'évaluation des capacités de suivi des instructions et de résolution de problèmes. Avec un nombre similaire de paramètres, des comparaisons sont à l'avantage de Ministral 3B par rapport aux modèles Gemma 2 2B (Google) et Llama 3.2 3B (Meta). Ministral 8B fait également mieux que Llama 3.1 8B.
Sur La Plateforme de Mistral, le tarif de Ministral 3B est de 0,04 $ par million de tokens, et 0,1 $ par million de tokens pour Ministral 8B. Les poids du modèle pour Ministral 8B sont disponibles pour une utilisation à des fins de recherche, tandis qu'une licence commerciale est requise pour Ministral 3B.

