


L’intelligence artificielle progresse à une vitesse folle, mais jusqu’ici, même les modèles les plus avancés se heurtaient à une barrière : le contexte limité. Impossible pour eux de digérer de longs documents ou de répondre rapidement à des questions complexes couvrant plusieurs pages.
Nvidia vient de frapper un grand coup avec la technologie Helix Parallelism, co-développée au sein de son architecture graphique Blackwell, qui promet de casser ce plafond de verre en offrant une inférence en temps réel pour des ensembles de millions de tokens.
Désormais, une IA peut traiter et synthétiser des informations issues de milliers de pages, et fournir une réponse claire, rapide et précise. Un tournant pour la recherche, l’éducation, la médecine…
Helix : l’IA qui comprend tout, même les romans
Jusqu’ici, les modèles d’IA étaient limités par ce qu’on appelle la « fenêtre de contexte » : au-delà de quelques milliers de mots, ils perdaient le fil. La technique Helix Parallelism change la donne en modifiant la façon dont fonctionne l'IA et en réduisant les goulots d'étranglement au niveau de la mémoire.
Jusqu'à présent, il fallait trouver un compromis entre la rapidité et la saturation de la mémoire mais en s'inspirant de la structure de l'ADN (d'où le terme Helix), en découplant les tâches mémoire et de traitement et les répartissant mieux au sein des groupes de GPU pour réduire les temps morts et les engorgements.
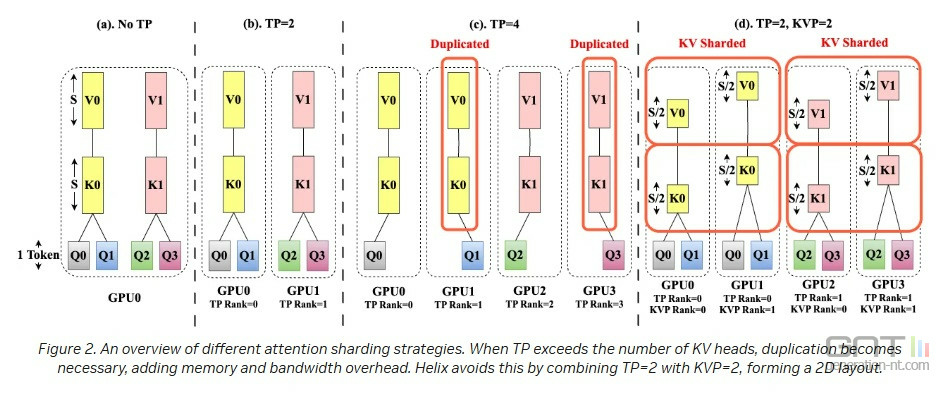
Nvidia fait travailler en parallèle les différentes composantes de l'IA : KV (Key-Value, le cache de tokens en mémoire) et FFN (Feed-Forward Network, le réseau neuronal), de manière à éviter la formation d'énormes caches de tokens et en privilégiant la réutilisation des mêmes ensembles de GPU pour réduire les temps de latence.
Grâce à une architecture inédite, ce système peut absorber et traiter des volumes de texte dignes d’une encyclopédie. Résultat : il devient possible de poser une question sur un livre entier, un rapport d’entreprise ou une base de données médicale, et d’obtenir une réponse instantanée, sans approximation.
Testée sur DeepSeek-R1 avec 671 milliards de paramètres, le temps de réponse amélioré de 1,5 fois. Cela peut également contribuer à multiplier par 32 le nombre d'utilisateurs accédant à la base encyclopédique pour un temps de latence donné.
Cette avancée ouvre la porte à des usages jusque-là impossibles. Imaginez un étudiant qui interroge une IA sur l’ensemble de ses cours, ou un médecin qui consulte un historique patient de plusieurs années en une seule requête.
Des réponses instantanées, même sur des sujets complexes
La technique Helix Parallelism de Nvidia est particulièrement intéressante dans le contexte des assistants virtuels nécessitant une fenêtre de contexte étendue mais tout en conservant un temps de réponse court (idéalement, quasi-instantané) et sur un mode conversationnel.

Nvidia Blackwell SuperPOD
Elle est particulièrement efficace avec l'architecture Blackwell et les clusters de GPU Nvidia pourront naturellement en tirer parti, constituant potentiellement un avantage concurrentiel en forçant les limites des systèmes IA traditionnels.
Il reste toutefois des limites encore intangibles de transferts de données dans les GPU créant des points de ralentissement malgré les optimisations. Et il est possible que la technique perde peu à peu de son efficacité à mesure que les modèles d'IA augmenteront encore leur capacité à ingérer des données, à moins de trouver de nouvelles façons de mobiliser de façon plus efficiente ces immenses quantités d'information.

