



Dans le giron de Google, la société britannique DeepMind - spécialisée dans l'intelligence artificielle et basée à Londres - a dévoilé la semaine dernière des progrès enregistrés dans l'apprentissage par renforcement.
DeepMind a développé l'algorithme DQN (Deep Q-network) qui associe le Q-learning avec un réseau de neurones profond. Le Q-learning est l'un des premiers algorithmes d'apprentissage par renforcement.
Sans connaître les règles et avec pour seule information le score et l'analyse des pixels affichés à l'écran, DQN peut apprendre à jouer à des jeux vidéo Atari 2600 et obtenir des scores supérieurs aux meilleures représentants du genre humain. La seule motivation du système est d'obtenir le meilleur score, ce qui l'incite à apprendre et constitue le principe de l'apprentissage par renforcement.
Mais l'algorithme Double DQN est encore plus performant dans cet exercice en réduisant les erreurs de l'ancien système et les surestimations observées. Avec 49 jeux Atari 2600, Double DQN peut surpasser les humains dans 31 jeux. La précédente version faisait mieux dans seulement 23 jeux.
Cela étant, DQN obtient parfois de meilleurs résultats que Double DQN. Par ailleurs, certains jeux continuent de poser des problèmes au système de DeepMind. Il échoue ainsi à des jeux comme Asteroids, Ms. Pac-Man ou encore Centipede. Le problème réside dans la stratégie à long terme.
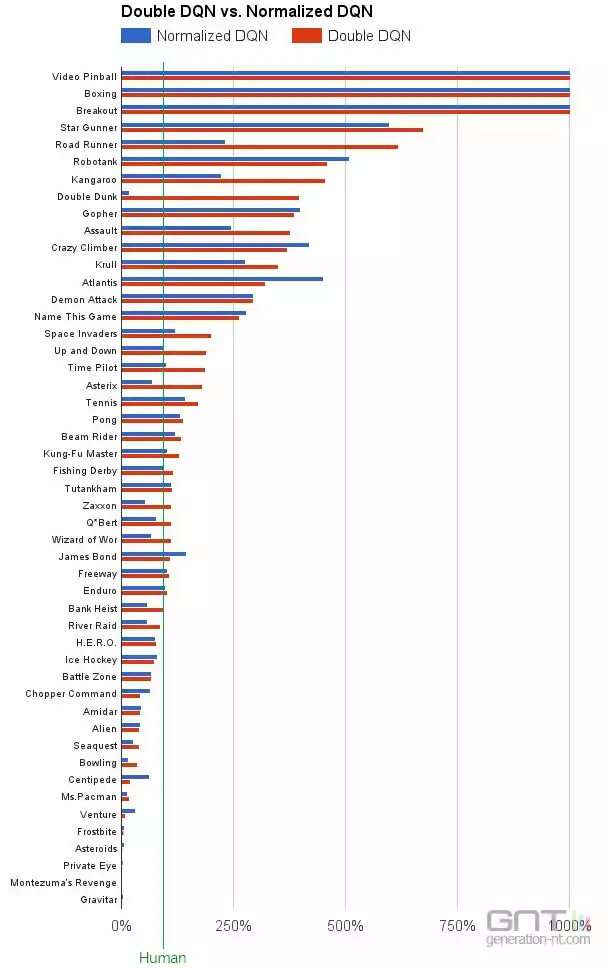
En début d'année, MIT Technology Review expliquait que le système de DeepMind regarde seulement les quatre dernières images de gameplay, soit environ un quinzième de seconde en arrière, pour apprendre quelles actions vont assurer le meilleur résultat.
On ne sait pas trop ce que Google compte faire des algorithmes de DeepMind mais il ne s'agira pas de jouer à des classiques...

