



Le lancement de l'IA chinoise DeepSeek R1 le 20 janvier a relancé une effervescence dans le secteur de l'IA après les annonces d'investissements massifs dans l'IA aux Etats-Unis qui donnaient l'impression d'une domination sans partage.
Le français Mistral AI en profite pour annoncer l'application mobile de son assistant IA Le Chat désormais disponible sur Android et iOS avec l'avantage de performances supérieures assurant des réponses quasi-instantanées aux prompts.
Outre la force d'un système Open Source, comme DeepSeek, Mistral AI met en avant la réactivité de son IA avec une capacité de sortie de 1100 tokens par seconde, contre 58 pour DeepSeek R1, 115 pour ChatGPT-4o ou 168 pour Gemini 2.0 Flash.
Le Chat, pertinent et rapide, comme un vrai
Cette capacité est permise par l'utilisation des ressources de la firme Cerebras Systems et de son environnement Cerebras Inference utilisée pour le modèle d'IA Mistral Large 2 de 123 milliards de paramètres.
Cerebras s'appuie sur une technologie de puces sur wafer constituant son offre WSE (Wafer Scale Engine). Plutôt que de s'appuyer sur des GPU, elle exploite des ensemble de puces rassemblés sur des wafers entiers et travaillant ensemble grâce à un système d'interconnexion et de généreuses quantités de mémoire unifiée.

Cette approche unique est bien adaptée aux besoins des modèles d'intelligence artificielle. La firme est soutenue par le fonds émirati G42 et ce type de solution est utilisé pour bâtir un réseau de supercalculateurs IA Condor Galaxy.
L'infrastructure derrière la performance de Mistral AI s'appuie sur les récents composants Wafer Scale Engine 3 annoncés en 2024 et rassemblant quelques 4000 milliards de transistors et 900 000 coeurs en une seule structure en wafer.
La fluidité des réponses, un plus grand confort d'utilisation
Cette inférence rapide, en permettant d'obtenir des réponses très rapidement, augmente grandement le confort d'utilisation des chatbots et la génération de code par IA.
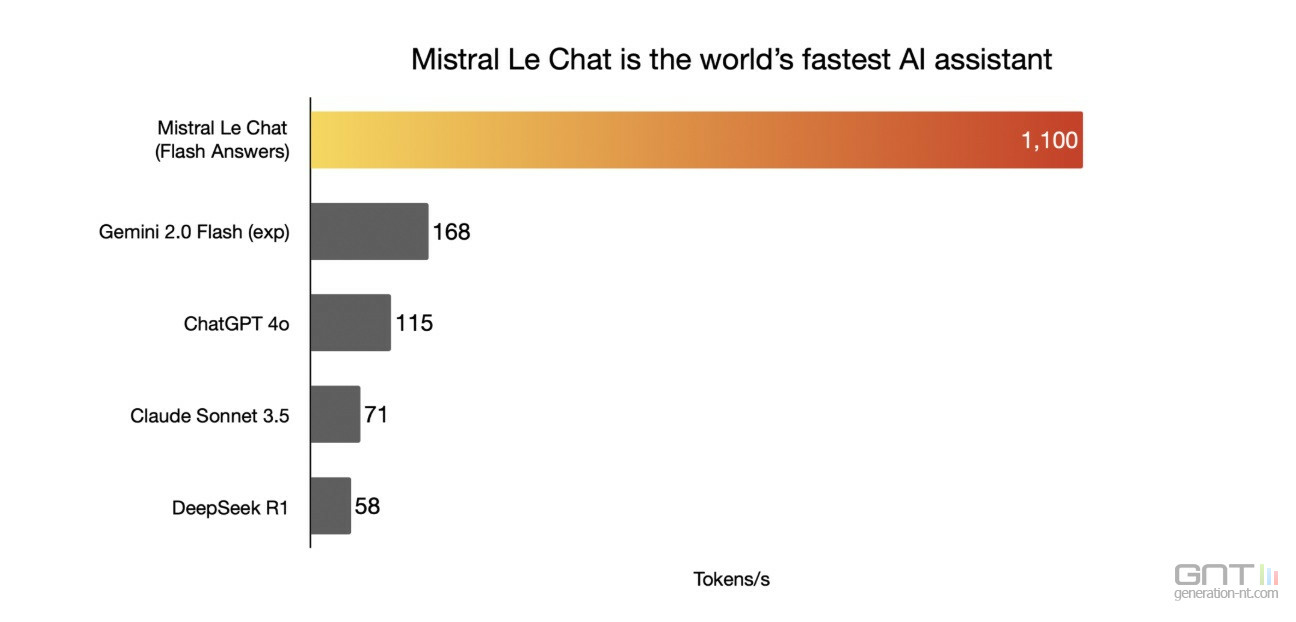
Le Chat de Mistral peut ainsi fournir des réponses en moins de 2 secondes quand Claude 3.5 Sonnet demande près de 20 secondes pour les mêmes requêtes, d'autres IA très utilisées pouvant même aller jusqu'à 50 secondes.
Les réponses fournies par Cerebras Inference sont d'ailleurs indiquées par une petite notification "Flash Answer" accompagnée d'un petit éclair affichée dans l'interface.
Pour cette première collaboration, Cerebras sera essentiellement derrière les requêtes texte des modèles d'IA de Mistral avant de s'étendre à d'autres capacités, chez le spécialiste français de l'IA et ailleurs.

