



Pour alimenter l'intelligence artificielle, que ce soit pour son entraînement ou son inférence, il faut des GPUs, beaucoup de GPUs et Nvidia en fait une spécialité qui lui a rapporté très gros en peu de temps.
Mais ce n'est pas la seule solution pour animer les grands modèles d'IA. La firme américaine Cerebras mise sur ses WSE (Wafer-Scale Engine), des solutions rassemblant des centaines de milliers de coeurs spécialisés IA sur un même wafer, tous connectés entre eux et travaillant de concert comme un seul processeur géant.

Cette approche se veut plus efficiente énergétiquement et aussi performante que les grands rassemblements de GPU réunis dans des centres de données IA. Cerebras a récemment fait parler d'elle en jouant sur la rapidité de réponse des modèles d'IA utilisant ses systèmes.
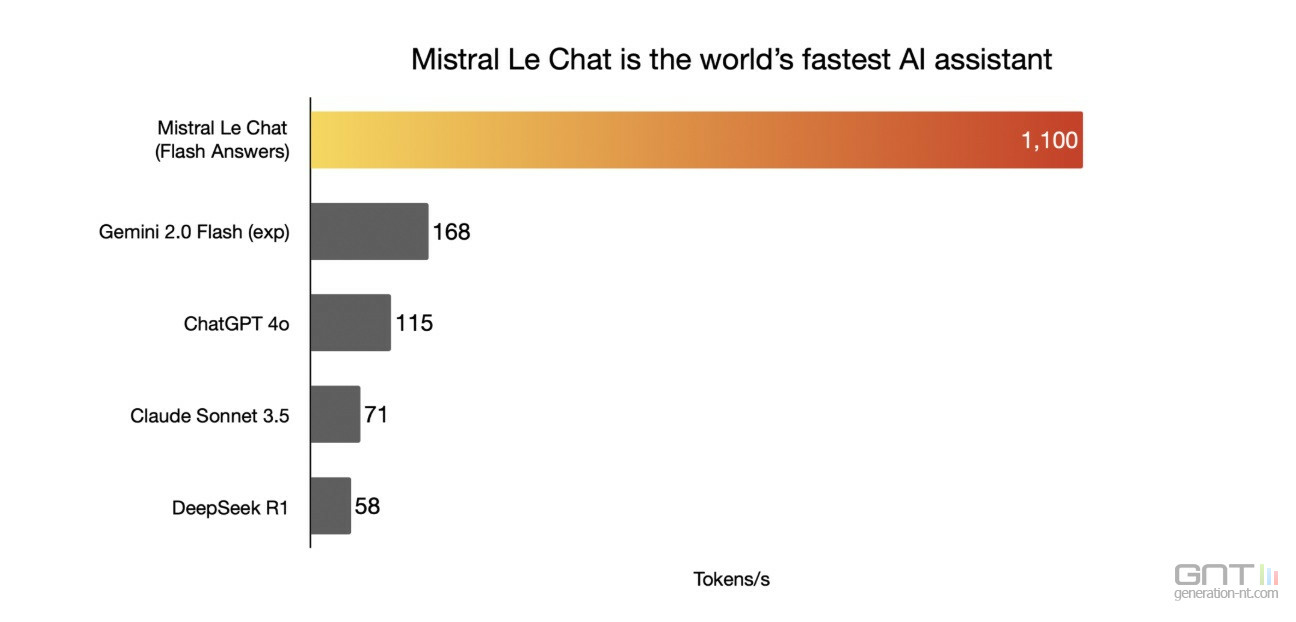
Du moteur de recherche IA Perplexity au français Mistral AI, les IA peuvent générer des réponses presque instantanément en utilisant les serveurs de Cerebras qui assurent des rythmes de sortie de plus de 1000 tokens/s, là où la vitesse de réponse d'autres IA très utilisées se compte en dizaines de tokens par seconde seulement, créant une latence entre la requête et la production d'une réponse.
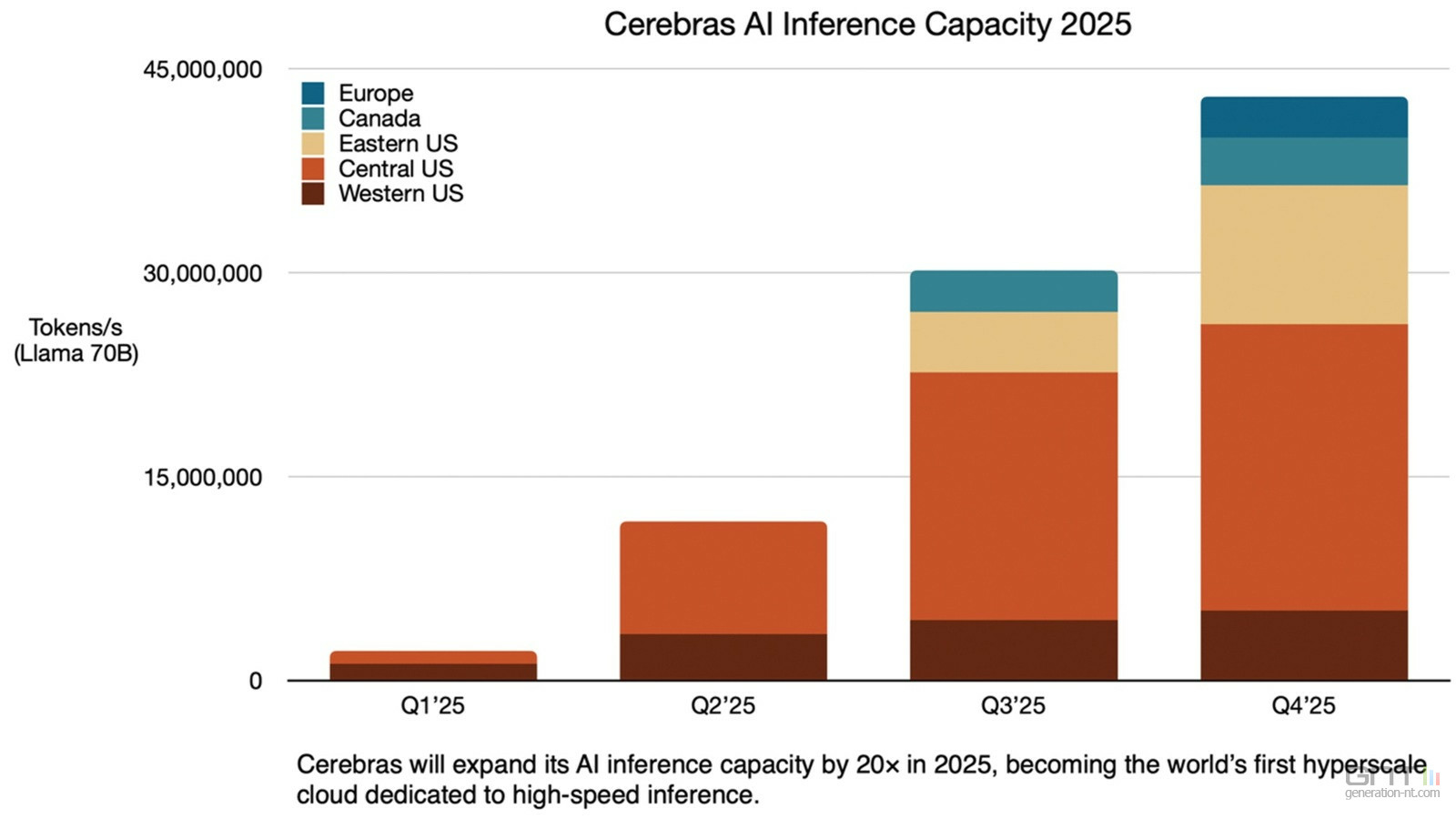
Six datacenters IA d'inférence, dont un en France
Ces qualités, Cerebras compte les déployer plus largement. La firme a du potentiel mais manque encore de gros clients pour assurer sa croissance. Pour changer d'échelle, elle annonce le lancement de six datacenters IA ces prochains trimestres qui apporteront une énorme capacité de production en sortie de 40 millions de tokens par seconde (sur une base de modèle d'IA Llama 70B) en inférence.
Le plus gros de ces centres de données est installé aux Etats-Unis mais l'un d'eux sera actif à Montreal (Canada) à partir du troisième trimestre et un autre sera lancé en France à la fin de l'année.
Cerebras compte sur la rapidité de réponse IA permises par ses installations rassemblant des milliers de systèmes Cerebras CS-3, bien supérieure à celles bâties sur des GPU, pour séduire de nouveaux clients, parmi lesquels ont comptera bientôt HuggingFace et AlphaSense qui ont fait des annonces en ce sens.
Elle revendique ainsi des temps de réponse entre 10 et 70 fois plus rapides que les solutions à base de GPU et dans un moment où les IA mettent en avant des capacités de raisonnement qui allongent naturellement leur temps de production d'une réponse, parfois de plusieurs minutes. Accélérer ce temps peut constituer un véritable atout.
Réactivité et faible coût, les atouts de Cerebras
C'est à la faveur de cette tendance qui gagne toute l'industrie IA que Cerebras compte faire la différence avec ses systèmes WSE-3 plus réactifs, qui prennent les accélérateurs IA de Nvidia en ligne de mire.
L'entreprise se dote également de cette grosse capacité d'inférence IA pour accueillir les futurs modèles d'IA comme Llama 4 de Meta ou les prochaines versions de DeepSeek, indique-t-elle à VentureBeat.
La vitesse de production de tokens, atout pour les modèles IA par raisonnement
L'autre axe de bataille de Cerebras est celui, tout aussi sensible, du coût. Et là encore, la firme prétend pouvoir le réduire d'un ordre de grandeur par rapport à ce que pratique OpenAI pour GPT-4, pour des performances IA similaires obtenues avec Llama 3.3 70B.
Coût moindre et plus grande rapidité, ce sont donc les deux principaux arguments face à Nvidia et ses composants IA qui restent la référence du marché, avec un intérêt particulier dans trois domaines : programmation, traitement de la vidéo et de la voix en temps réel et modèles IA capables de raisonnement.
En se focalisant sur des domaines précis, c'est aussi un moyen de trouver des niches face aux géants du cloud dotés d'infrastructures massives très polyvalentes. Il reste maintenant à convaincre les clients.

