



L'irruption de l'IA DeepSeek ce 20 janvier a fait l'effet d'une bombe dans le monde de l'IA en offrant des performances similaires ou supérieures à celles des grandes IA nord-américaines pour un coût bien plus bas.
Le chiffre de 6 millions de dollars a été avancé, sans beaucoup de précisions sur ce qu'il recouvre (entraînement, inférence, les deux ?) et mis en opposition aux milliards de dollars dépensés en infrastructures spécialisées aux Etats-Unis.
Le cabinet d'analyse SemiAnalysis s'est penché sur le sujet et remet en cause cette notion d'un succès obtenu avec des moyens très légers de 2048 accélérateurs IA Nvidia A800 respectueux des restrictions imposées par les USA.
Le secret viendrait de l'utilisation de techniques de renforcement d'apprentissage venant compenser les limites de la puissance de calcul brute fournie en arrière-plan.
Ce narratif, sans être complètement réfuté, est en train d'être remis en cause à la fois par rapport aux performances, avec les problématiques de distillation d'IA qui auraient permis de faciliter l'accroissement des performances en puisant dans les données des grands modèles d'IA, mais aussi sur la réalité de l'infrastructure IA en coulisse.
Bien plus que 6 millions de dollars
Pour SemiAnalysis, DeepSeek exploite une gros dispositif de 50 000 accélérateurs IA Nvidia Hopper, distribué entre 10 000 composants H800, 10 000 Nvidia H100 et des accélérateurs H20, et qui représenterait un coût de 1,6 milliard de dollars, dont 900 millions de dollars en coûts opérationnels pour faire tourner les serveurs.
Les analystes notent également que High Flyer, le Hedge Fund derrière DeepSeek, a dépensé des centaines de millions de dollars en investissements GPU divers, assez loin de l'image de la petite startup démarrant avec très peu de moyens.
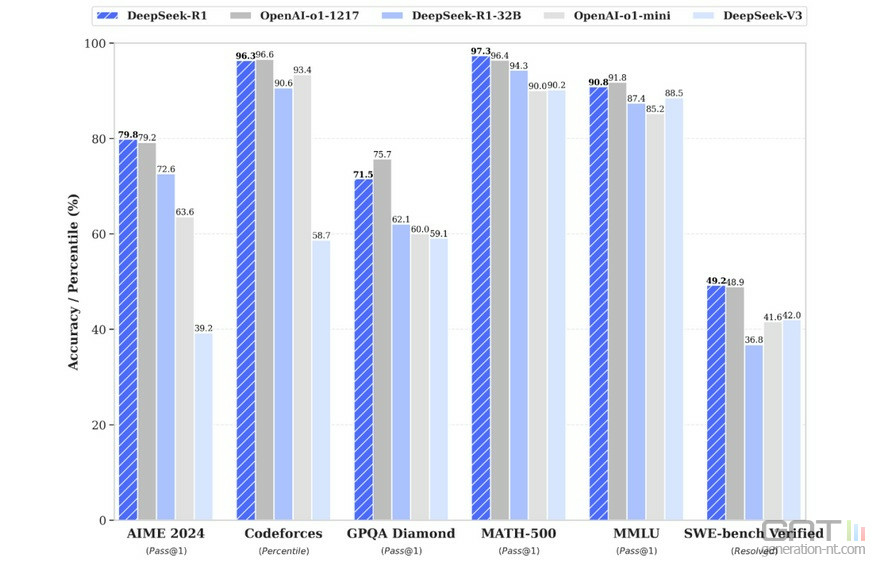
DeepSeek R1, au niveau d'o1 d'OpenAI
Cela donne tout de même l'avantage à DeepSeek de disposer en bonne partie de ses propres datacenters, là où beaucoup de startups doivent louer des capacités, ce qui permet d'avoir un contrôle total sur ce qui est fait sur la liberté de mener des optimisations expérimentales sur ses modèles d'IA. D'autre part, DeepSeek bénéficie d'un vivier de talents en Chine et la très grande majorité des recrutements se fait au niveau national.
Pour SemiAnalysis, l'histoire de DeepSeek V3 mis en place avec seulement 6 millions de dollars est belle et alléchante mais erronée, ce qu'avaient déjà pointé plusieurs spécialistes de l'IA, et ce chiffre ne correspondrait qu'au coût du pré-entraînement de l'IA, soit une petite portion de l'ensemble de la structure de coût, mais a tout de même de solides bases pour apporter quelque chose au marché de l'IA et faire bouger les lignes.
Concernant les performances et le fait que DeepSeek V3 offre des capacités similaires à GPT-4o d'OpenAI, ce qui a beaucoup impressionné, SemiAnalysis est de même manière plus réservé sur la prouesse telle qu'elle a été présentée jusqu'à présent.
D'abord parce que GPT-4o date de mai 2024 et que les progrès sont fulgurants dans l'IA mois après mois, en partie grâce aux efforts des startups de l'IA travaillant beaucoup à l'optimisation des algorithmes, axe stratégique à côté de l'augmentation brute des capacités de calcul et qui est aussi le grand espoir pour les petites startups de trouver un espace parmi les géants de l'IA aux énormes moyens financiers pour acheter des centaines de milliers de GPU.
Du renforcement d'apprentissage pour optimiser, de la distillation pour faciliter
Les améliorations offriraient ainsi des progressions d'un facteur 4 annuellement (soit 4 fois moins de puissance de calcul pour arriver au même résultat en inférence chaque année) et dans certains cas d'un facteur 10.
C'est ce qui permet par exemple à un modèle GPT-3 de tourner correctement sur un ordinateur portable actuellement alors qu'il lui a fallu un supercalculateur pour l'entraînement et une collection de GPU pour l'inférence à ses débuts.
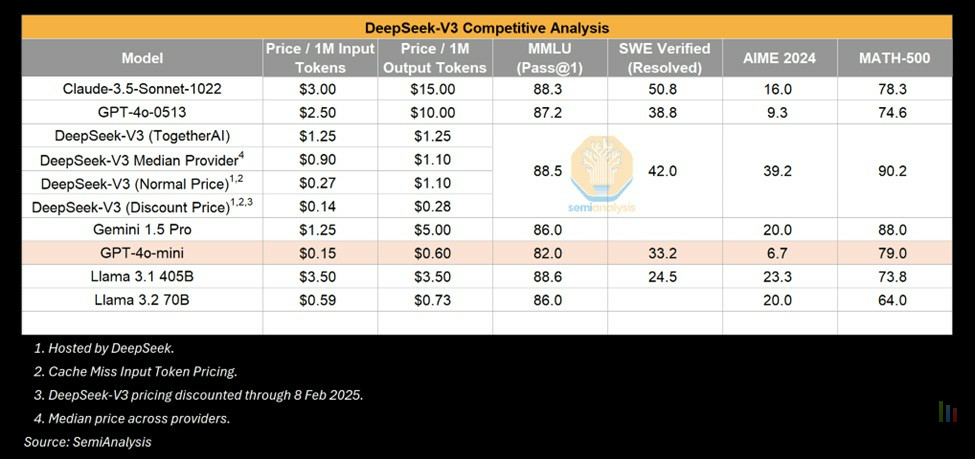
Si la performance de DeepSeek n'est donc en réalité pas totalement sortie de nulle part, il est à mettre à son crédit la capacité de le faire avec une structure de coûts réduite et pas mal d'astuce en optimisation algorithmique, en matière de pré-entraînement mais aussi post-entraînement, dans l'utilisation du modèle MoE (Mixture of Experts) mis au service de l'efficience du modèle d'IA par rapport à sa capacité de calcul disponible.
Une partie de ces innovations reste à documenter publiquement au fil d'articles qui seront sans doute très suivis et il reste la problématique de la distillation qu'aurait utilisée DeepSeek pour améliorer plus vite les résultats de son modèle.
Les observateurs notent d'ailleurs que DeepSeek R1 n'a pas publié certaines informations, dont la puissance de calcul, sans doute pour ne pas confirmer implicitement qu'un plus grand nombre de GPU que prétendu a été utilisé.

