



S'appuyant sur une version optimisée 3.5 du modèle de langage Generative Pre-trained Transformer (GPT), l'agent conversationnel ChatGPT d'OpenAI impressionne sur plusieurs plans, dont la qualité de sa rédaction quand il génère du texte en langage naturel. Même si cela repose au final sur de la prédiction de mots, le résultat est saisissant.
La technologie d'IA de ChatGPT repose sur 175 milliards de paramètres et a été entraînée avec des centaines de milliards de textes comme des articles en ligne, des livres et des publications universitaires. La base de connaissances de ChatGPT s'arrête cependant à 2021.
Les algorithmes de machine learning permettent de produire des réponses, tandis que des techniques d'apprentissage supervisé et par renforcement contribuent à affiner les résultats pour éviter des écueils. Cela étant, ChatGPT peut quand même donner des informations factuellement fausses avec un aplomb désarmant.
Un classificateur proposé par OpenAI
Un tour de force d'OpenAI a été de proposer un accès libre et gratuit à ChatGPT. C'est désormais également le cas pour un outil qui a été entraîné afin de distinguer les textes écrits par une IA de ceux écrits par un humain.
Ce classificateur ne cible pas uniquement ChatGPT qui suscite notamment des craintes de triche par des étudiants, ou encore pour des manipulations avec des campagnes de désinformation. OpenAI le présente comme une prédiction de la probabilité qu'un texte soit généré par IA.
Le modèle de langage utilisé a été entraîné sur un jeu de données comprenant des " paires de textes écrits par des humains et des textes écrits par IA sur le même sujet. "
Loin d'être la panacée (et seulement pour l'anglais)
Reste que la pertinence de l'outil est jugée " très peu fiable " sur les textes courts de moins d'un millier de caractères. Même au-delà, OpenAI écrit qu'il est " impossible de détecter de manière fiable tous les textes écrits par une IA. "
Le classificateur d'OpenAI est par ailleurs recommandé pour des textes en anglais. Ses performances sont jugées " nettement moins bonnes " dans d'autres langues. En cause, un entraînement principalement sur des textes en anglais.
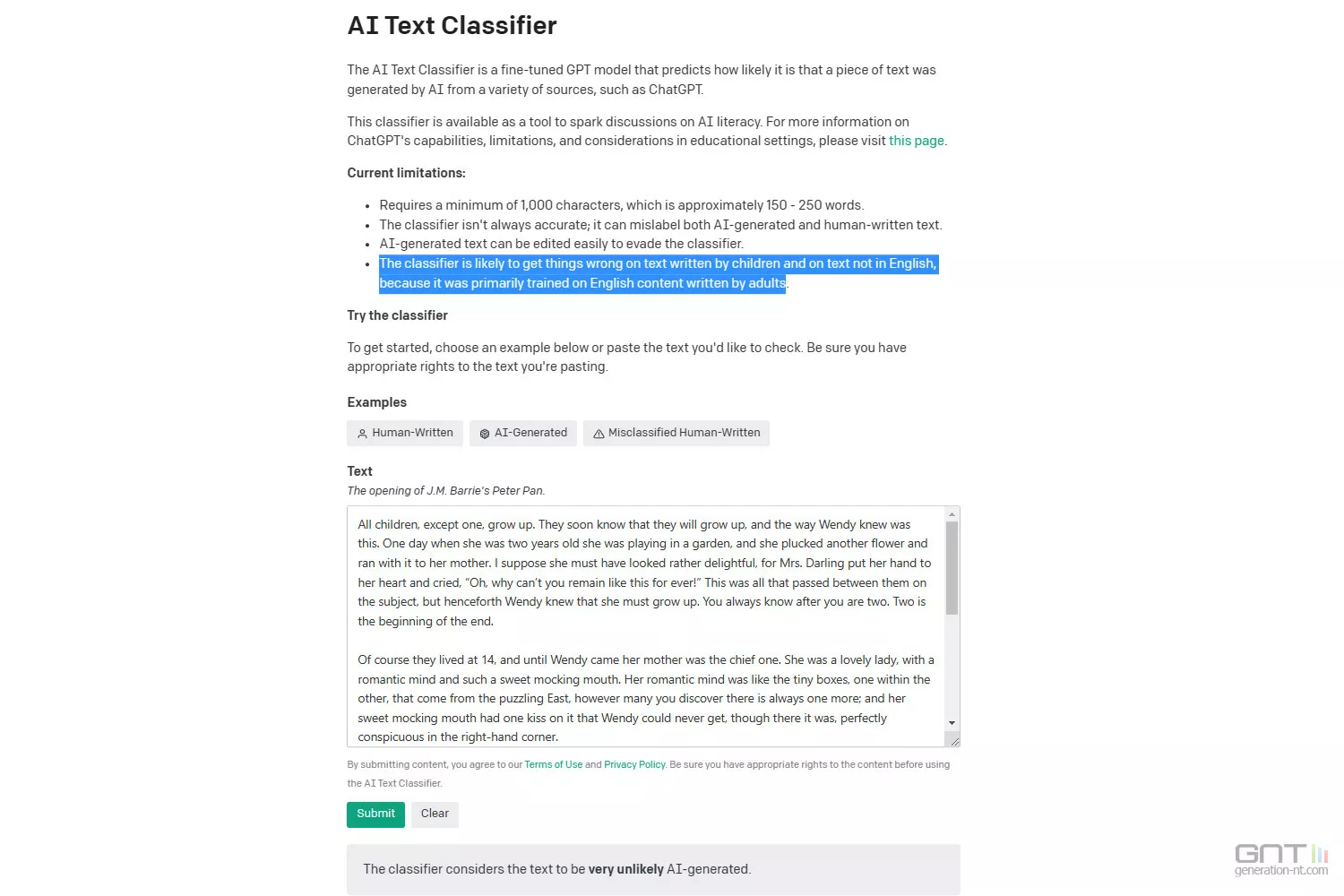
Selon la propre évaluation d'OpenAI sur des textes en anglais, l'outil a identifié correctement 26 % de tous les textes écrits avec de l'IA. Pour des textes écrits par des humains, il y a eu des faux positifs dans 9 % des cas. Ils ont été attribués à de l'IA.
" Nous mettons ce classificateur à la disposition du public afin de recueillir des commentaires sur l'utilité d'outils imparfaits comme celui-ci. Notre travail sur la détection des textes générés par IA se poursuivra et nous espérons pouvoir partager des méthodes améliorées à l'avenir. "

