



Même s'il recouvre des réalités très diverses et est encore souvent mis à toutes les sauces pour impressionner un auditoire, le concept de l'intelligence artificielle fait l'objet de toutes les attentions de la recherche scientifiques et des industriels, avec une augmentation exponentielle des publications et dépôts de brevets depuis 2012 environ.
C'est ce qui ressort d'un rapport sur l'IA de l'Organisation mondiale de la propriété intellectuelle (OMPI ou WIPO en anglais), et qui tend à confirmer qu'il s'agit d'une tendance de fond et pas seulement d'un phénomène de mode sur le point de se dégonfler aussi vite qu'il est apparu, même si ses effets se jouent souvent surtout en coulisses.
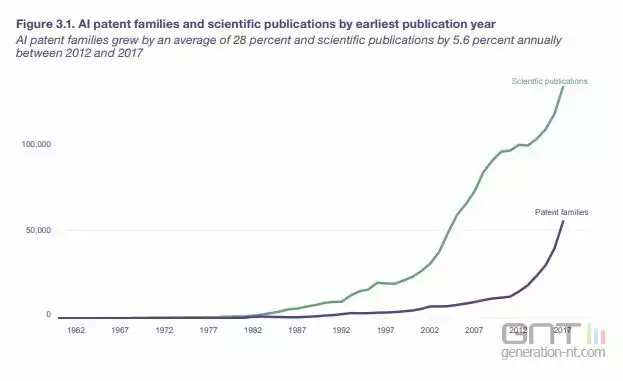
Rien que sur 2017, plus de 55 000 brevets relatifs à l'IA (au sens large) ont été déposés, tandis que plus de 130 000 publications scientifiques ont vu le jour. Si depuis les années 90, les publications ont vu leur rythme s'accélérer, l'augmentation rapide du nombre de brevets trouve un point d'inflexion en 2012, avec la finalisation de l'outil de reconnaissance visuelle AlexNet, conçu par des chercheurs de l'Université de Toronto, rappelle le journal Les Echos, tandis que des chercheurs de Google et Stanford publiaient un article démontrant des capacités de reconnaissance d'objet (ici des chats dans des vidéos Youtube) grâce au deep learning.
Les données de l'OMPI montrent ainsi une forte poussée des brevets concernant la reconnaissance visuelle après 2012, loin devant d'autres techniques de reconnaissance (la parole et le langage, notamment). Plus généralement, le deep learning est la compétence de l'IA qui a le plus fait l'objet de dépôts de brevets, et sans le temps de maturation habituel après les publications scientifiques.
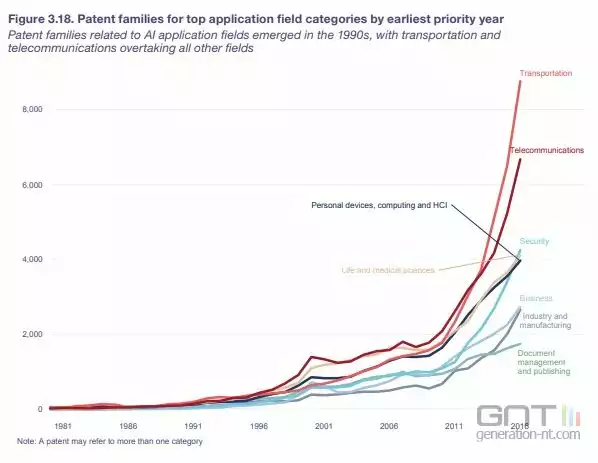
Concernant les brevets, les principaux secteurs intéressés par la reconnaissance visuelle sont, de loin, les transports suivis des télécommunications avec, sans surprise pour le premier, un focus principal sur la voiture autonome.

