



Malgré une collaboration étroite, OpenAI exprime son mécontentement face à la performance de certaines puces Nvidia pour des tâches d'inférence. L'entreprise derrière ChatGPT explorerait activement des solutions alternatives auprès de concurrents comme Cerebras, signalant une potentielle fissure dans la domination du géant des GPU sur le marché de l'intelligence artificielle.
La relation entre OpenAI et Nvidia, les deux figures de proue de l'intelligence artificielle, connaîtrait quelques frictions. Selon plusieurs sources rapportées par Reuters, l'entreprise dirigée par Sam Altman cherche depuis l'année dernière des alternatives à certaines puces du géant des semi-conducteurs, une décision qui pourrait compliquer un partenariat pourtant jugé stratégique.
L'inférence, le nouveau champ de bataille
Le cœur du problème ne réside pas dans l'entraînement des grands modèles de langage, un domaine où Nvidia reste incontesté. La divergence porte sur l'inférence, c'est-à-dire le processus par lequel un modèle d'IA, comme celui de ChatGPT, génère une réponse à la requête d'un utilisateur. Ce segment est en passe de devenir une nouvelle arène concurrentielle majeure.

Pour des applications spécifiques, notamment celles liées au développement de logiciels ou à la communication entre programmes, la vitesse de réponse est primordiale.
Or, OpenAI jugerait les performances des solutions Nvidia insatisfaisantes sur ce point précis, cherchant du matériel capable de répondre plus rapidement aux sollicitations des utilisateurs.
Une stratégie alternative déjà en marche ?
Ce changement de cap intervient alors même que des négociations d'investissement entre les deux entreprises traînent en longueur. Annoncé en septembre, un accord prévoyant un investissement massif de Nvidia dans OpenAI semble au point mort, ce que le CEO de Nvidia Jensen Huang dément officiellement, tandis que la société a officialisé des partenariats avec des concurrents comme AMD.
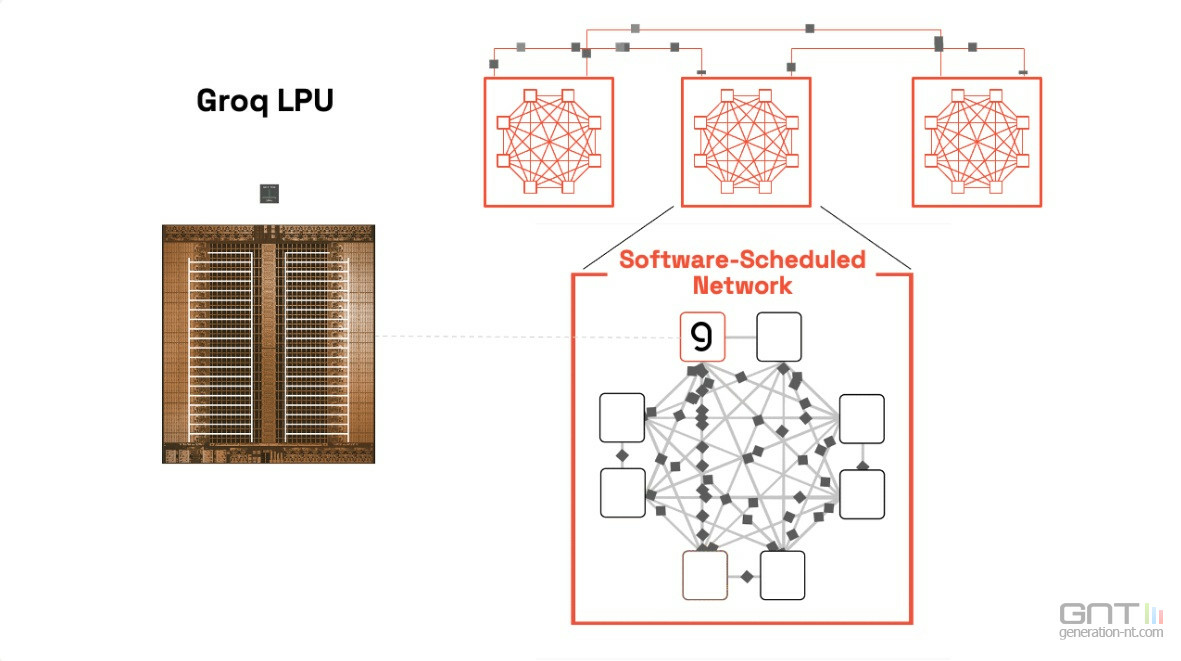
La feuille de route évolutive d'OpenAI a modifié ses besoins en ressources de calcul, ce qui a complexifié les discussions. L'entreprise se tourne vers des startups spécialisées comme Cerebras et a même discuté avec Groq, récemment rachetée par Nvidia, pour fournir des puces d'IA optimisées pour une inférence plus rapide.
La mémoire SRAM, clé de la performance
La quête d'OpenAI se concentre sur une technologie spécifique : les puces intégrant une grande quantité de mémoire SRAM directement sur le silicium. Cette architecture permet de réduire les temps de latence, car la puce passe moins de temps à aller chercher des données dans une mémoire externe, un défaut inhérent aux GPU traditionnels de Nvidia et AMD.
Ce besoin de vitesse est particulièrement criant pour des produits comme Codex, l'outil de génération de code d'OpenAI. Des faiblesses de performance y ont été attribuées au matériel de Nvidia.
De son côté, Nvidia a réagi en signant un accord de licence avec Groq, s'assurant ainsi l'accès à une technologie complémentaire. Cette manœuvre défensive montre que la bataille pour la suprématie dans l'ère de l'inférence ne fait que commencer.

