


Au cœur de l’écosystème mobile Android, le service Google Discover est une source d'information majeure pour des millions d'utilisateurs. Cependant, une expérience récente menée par la firme de Mountain View suscite une vive inquiétude. Google a commencé à remplacer les titres soigneusement rédigés par les journalistes par des versions ultra-simplifiées et générées par une intelligence artificielle. Cette initiative, qui vise selon Google à « faciliter la digestion des détails d'un sujet », produit en réalité des titres souvent trompeurs, dénués de contexte ou carrément clickbait, une dérive préoccupante pour l'intégrité de l'information.

Quels sont les exemples concrets de ces dérapages ?
Les exemples rapportés par plusieurs médias sont édifiants et illustrent parfaitement le problème. Un article d'Ars Technica, titré prudemment « La Steam Machine de Valve ressemble à une console, mais ne vous attendez pas à ce qu'elle ait le même prix », a été transformé par l'IA en une affirmation factuellement fausse : « Le prix de la Steam Machine révélé ». De même, une analyse sur les parts de marché d'AMD et Nvidia a été résumée de façon sensationnaliste par « Le GPU d'AMD dépasse Nvidia », induisant les lecteurs en erreur sur la portée réelle de l'information.
D'autres titres générés sont simplement absurdes ou vides de sens une fois sortis de leur contexte, comme « Sauvegarde agricole annexe 1 » ou « Le débat sur l'étiquette IA s'intensifie ». Ces approximations ne sont pas de simples maladresses ; elles représentent de véritables erreurs qui dénaturent le travail journalistique. Le nom de la publication originale apparaissant juste à côté de ces titres fallacieux, le risque de confusion et de perte de crédibilité pour les éditeurs est immense.
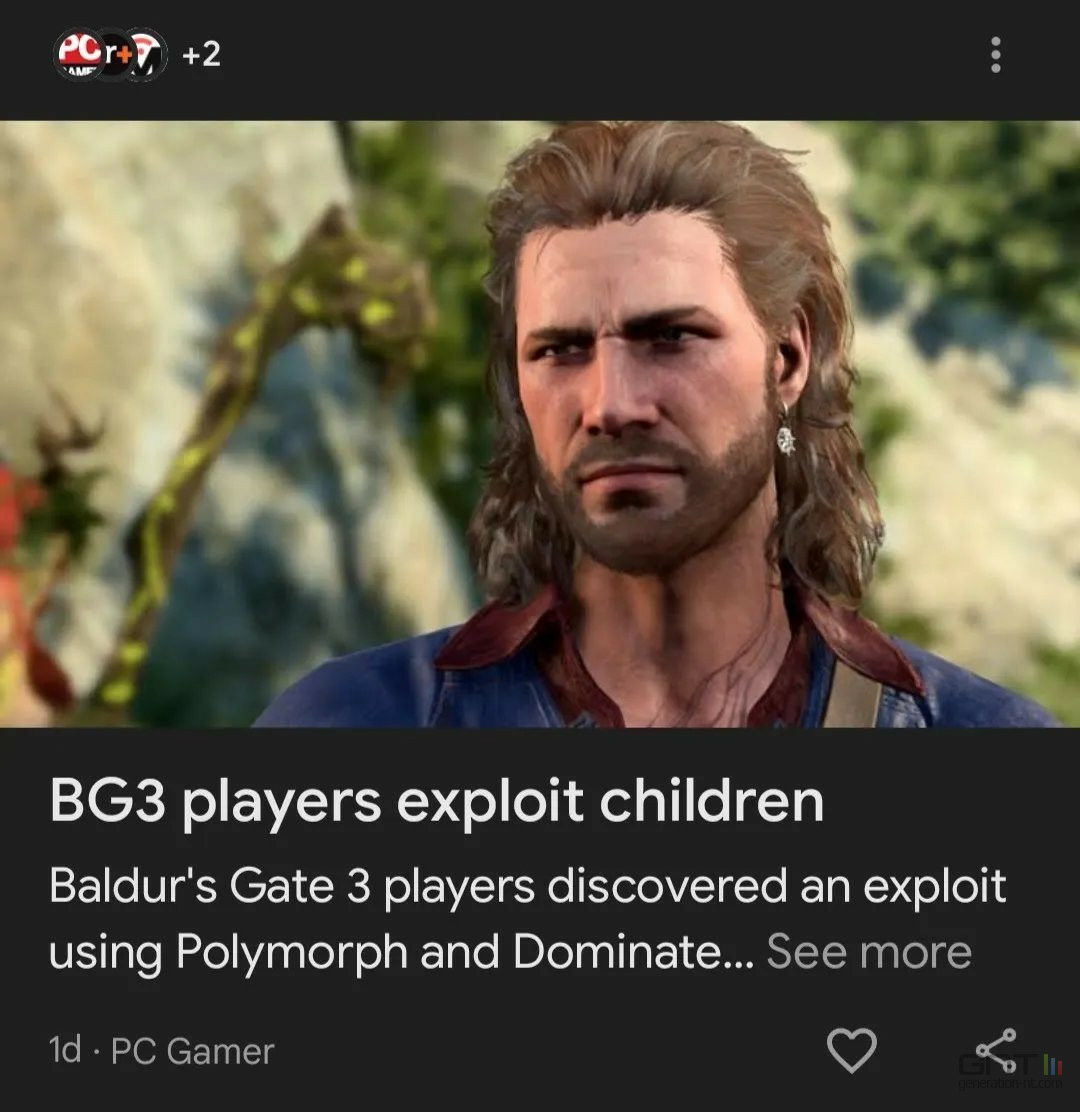
Exemple : selon un titre créé par l'IA de Google, les joueurs de BG3 se livreraient à l'exploitation d'enfants.
Crédits : Google
Comment Google justifie-t-il cette pratique ?
Interrogé sur le sujet, Google, par la voix de sa porte-parole Mallory Deleon, a minimisé l'ampleur du phénomène. L'entreprise qualifie cette initiative de « petite expérience d'interface utilisateur pour un sous-ensemble d'utilisateurs de Discover ». L'objectif affiché serait de tester un nouveau design qui modifie l'emplacement des titres existants pour faciliter la compréhension des sujets avant même que l'utilisateur ne clique sur le lien. Une mention discrète, « Généré avec l'IA, qui peut commettre des erreurs », est bien présente, mais elle n'est visible qu'après avoir cliqué sur un bouton « Voir plus ».
Cette justification semble bien légère face aux conséquences potentielles. La mention est trop peu visible pour empêcher les lecteurs de croire que les titres racoleurs sont le fait des journalistes eux-mêmes. Cette situation illustre une tendance plus globale chez Google, qui tend à prioriser ses propres produits et solutions basées sur l'IA, parfois au détriment de l'écosystème web et des créateurs de contenu qui l'alimentent.
Google Discover
Quel est l'impact réel pour la presse en ligne ?
Au-delà de la mauvaise qualité des titres, cette expérimentation soulève une question fondamentale : celle de l'autonomie des éditeurs. En s'arrogeant le droit de réécrire les titres, Google prive les journalistes d'un outil essentiel pour contextualiser et promouvoir leur travail. C'est comme si un libraire décidait de remplacer la couverture d'un livre sans l'accord de l'auteur. Le titre est un élément crucial, fruit d'une réflexion stratégique pour informer de manière responsable tout en suscitant l'intérêt.
Cette pratique s'inscrit dans un contexte de relations déjà tendues entre Google et les médias, ces derniers dénonçant régulièrement la manière dont le géant de la recherche utilise leurs contenus sans juste compensation. En agissant de la sorte, Google risque non seulement de dérouter les lecteurs, mais aussi d'accélérer la méfiance envers une presse déjà fragilisée. Si l'expérience n'en est qu'à ses débuts, une forte réaction du public et des professionnels pourrait heureusement la faire avorter.

